A short CSI story with a hidden suspect
The other day I had an interesting problem involving an unstable SQLserver AG cluster on a virtual machine (EC2) in Amazon’s AWS. It appeared that if a data integrity job and an index rebuild job overlap, the node simply went unresponsive and got evicted.
A failover kicked in and we could only revive the primary node by rebooting and revert the node-eviction. What on earth could have caused this? I have never seen a server go down because of a standard OLA maintenancejob on an RDBMS, so the troubleshooter in me was intrigued what was going on. Such a severe and reproducible problem didn’t seem a small bug to me, but instead it seemed we hit on a misunderstood concept.
How it started
So let me tell you what happened on day 1, when we first got a notification of the node failover. At first we didn’t know what caused the breakdown so Pavlov made us look at the different logfiles to collect diagnostic data and come up with possible reproduction scenario’s. (You might have a look at the Microsofts TigerToolbox for Failover Analyses here)
We saw a few telling entries and some red herrings, such as the loss of connection with the witness server. The primary node lost all network connectivity, but wasn’t that simply a sign of resource starvation?
Also, the problem seemed to occur after the windows OS has had a patch. That got us sidetracked for a while before we ruled this out as a coincidence.
The first solid clue came when we noticed that the problem occurred around the same time in the evening. There was little activity on the database, except a daily index rebuild and corruption check, as demanded by the vendor of the application. Surely an index rebuild couldn’t lead to starvation to such an extend that the instance is brought down? Moreover, we just had the instance increased in both memory and CPU resources by a factor 4. To make it even more interesting: Before the fourfold increase of the serversize we didn’t had any problems.
Is it the infrastructure?
And there I got my first suspicion: it had to do with the infrastructure footprint we’re placing. This came with a little problem: it was hosted in the cloud, where we didn’t have access to overcommitment figures, settings and logfiles on the infrastructure. Also there were some cloud specific details to consider, some of which I had not heard before. For example, in an unrelated incident where a downscaling of a node took me a few days because of G2 storage credit starvation(?). Over the years I’ve read all the fine print there is of SQLserver, but on Amazon, not so.
This is going to be a learning experience.
Memory starvation
The final hint came from a different source. Someone from cloudops couldn’t start up a database server as this sometimes hit upon a resource limit. Aha! We’re in some sort of resource consumption group, I should have investigated the contract with the Cloudprovider more closely. I hadn’t done that yet. After all, the cloud is like a tap for resources and in this wonderful brave new scalable world there shouldn’t be something like resource limits, no?
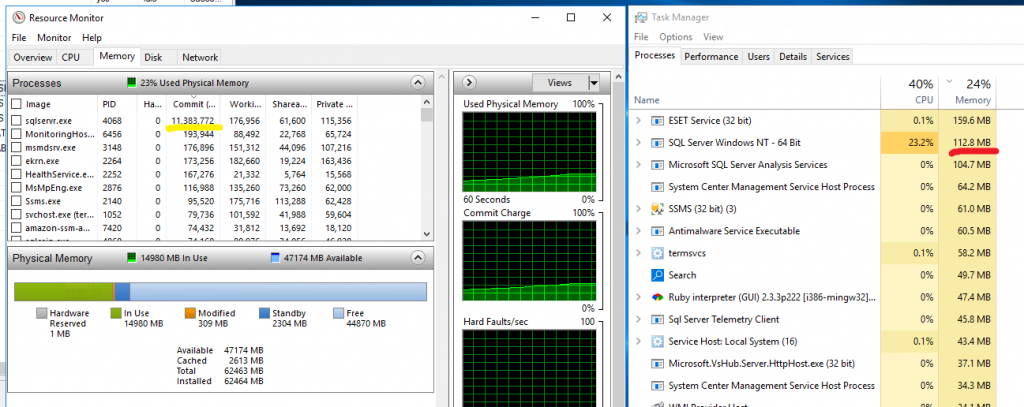
My suspicion was with memory starvation and I noticed some funnies: According to the task manager, the SQLserver takes 112 Megabyte, but the resource monitor showed a reserved amount of over 11GB.
I now had a suspect, guilty by association: the ‘Locking Pages in Memory’ setting. This is a setting for SQLserver in a virtual machine environment to keep the memory reserved for the database. The so-called balloon driver process snatches away any unused memory from the virtual machines, which is not a good idea for software like databases who rely heavily on cache for their performance.
Indeed, after removing this setting (in the group policy, for details see here) the crash didn’t occur anymore and both the taskmanager and the resourcemanager now showed a consistent picture.
Lesson?
Being a database engineer I like to know the performance and setup of the underlying infrastructure. I didn’t bother to check this out with Amazon, assuming that I would not be able to see any log or errors on their side. But they do have some fine print, which I need to heed if I want to be able to advice on the best buy in the cloud.